!! 구 블로그 (Blogger) 에서 가져온 글입니다. 글 일부가 깨져보일 수 있습니다.
그리고 수행평가용이라서 분석을 개판으로 했습니다. 이 글을 다른 어딘가에 인용하지 마세요.
왜 이런 짓을 하는가?
학교에서 벤포드 법칙과 관련하여 활동을 해서 소감문을 제출하라고 한다.
물론 학교에서는 통계청에서 제공하는 데이터 차트 같은
한 만개에서 십만개 정도 데이터를 조사하라고 하긴 했는데, 마침 친구가 나무위키의 약 50만개 문서 (리다이렉트, 사용자문서 제외)의
5천만개 숫자를 가지고 분석을 돌렸길래 나는 좀더 크게 영문 위키피디아에 있는 숫자들을 대상으로 조사하기로 했다.
벤포드 법칙이란?
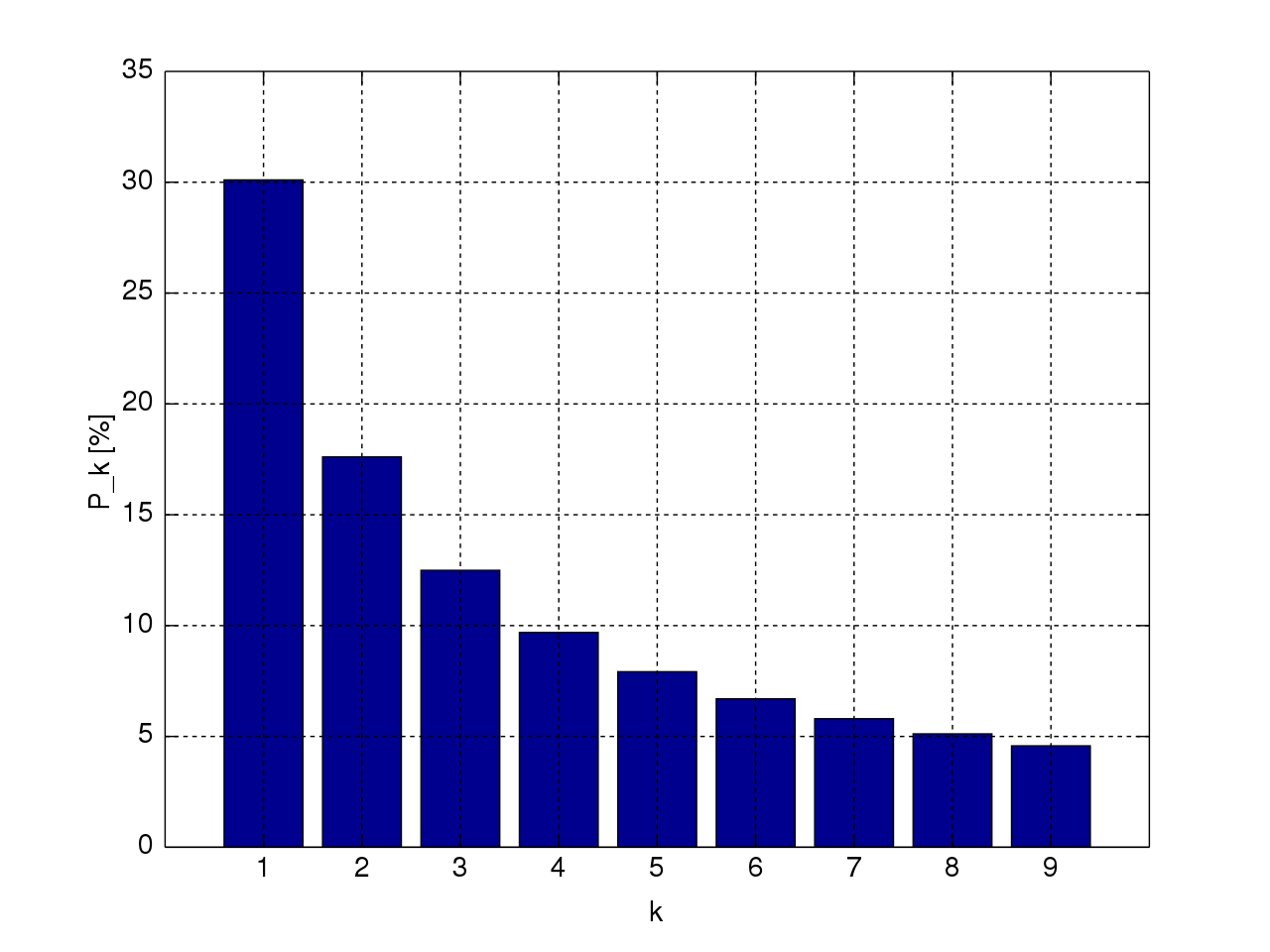
우선 분석 글을 시작하기 전에 벤포드 법칙이 무엇인지부터 간단히 설명을 하고 시작을 하겠다.
벤포드 법칙이란 1938년에 물리학자 프랭크 벤포드가 자기 논문에서 제시한 법칙으로, 간단히 말하면 "수치를 나타내는 수"에서 수의 첫자리가 낮을 확률이 높다 라는 간단하지만 신기한 법칙이다. 자세한 설명은 나무위키가 해줄 것이다.
1. 위키피디아 데이터베이스 덤프 다운로드
우선 분석을 하기 위해서는 당연하지만 위키피디아의 데이터베이스가 필요하다. (위키피디아 전체를 크롤링하기에는 아주 오래걸릴 뿐더러, 위키피디아의 서버에 부하를 주기 때문에 가능성은 낮겠지만 크롤링하는 중간에 위키피디아에서 접속을 차단할 수도 있다.)
다행히도, 위키피디아는 우리 같이 위키피디아의 데이터베이스를 활용하려는 사람들을 위해서, (물론 위키피디아 서버를 백업하려는 목적도 있지만) 위키피디아 전체의 XML 덤프를 제공한다.
여기에서 위키피디아의 데이터베이스를 비트토렌트를 이용하여 다운로드 할 수 있다. 토렌트 말고 직접 다운로드 링크도 주어지지만... 속도가 처참하기 때문에 토렌트로 다운로드 하는 것을 권장한다. (약 2~3 MB/s의 속도로 다운로드가 되는데, 총 파일이 20GB가량 되기 때문에 서너시간 정도 걸린다. 물론 토렌트 특성상 더 빠를수도 느릴수도 있다.)
그리고 bz2 압축을 해제한다. 윈도우라면 위대하신 반디집을 이용하여 압축을 해제할 수 있고, 리눅스면 bzip2를 이용하면 해제할 수 있다. 뭐 리눅스 유저면 알아서 찾겠지...
압축을 해제하면 80기가 정도의 XML 파일 하나가 생긴다. 이 파일을 잘 저장하자.
2. 분석 프로그램 작성
이 80기가에 달하는 어마무시한 파일을 분석하기 위한 프로그램을 작성한다.
Rust를 이용하여 프로그램을 작성하였는데, 자세한 코드는 깃허브가서 보고,
대충 여기서는 사용한 정규표현식만 나열하도록 한다.
- (shell\|1=) : 위키피디아 문서의 절반 이상을 차지하는 리다이렉트 문서를 대상에서 제외한다.
- ([^0-9 ]) : 문서에서 숫자와 공백만 남긴다.
- (\s[1-9][0-9][0-9][0-9]\s) : 년도일 가능성이 큰 네자리 숫자를 싹다 날려버린다. 위키피디아 숫자의 30%정도가 년도다...
- (0) : 0을 날린다. 0은 분석에 사용되지 않는다.
- ([^\s]\d) : 숫자의 앞자리만 남긴다.
- (\s) : 공백을 제거한다.
3. 분석 돌리기
그렇게 작성한 프로그램을 컴퓨터로 돌리...는데 3초에 1000페이지라는 정말 느린... 속도..로 작업이 되고 있었다.
위키피디아의 문서(Article)이 600만개가 넘고, 페이지는 더 많다는 걸 감안했을 때 며칠밤을 꼬박새서 작업을 해야 끝날 속도였다.
아니 대체 왜 이런 느린 속도가 나오나 봤더니 Rust의 정규표현식 라이브러리가... Python보다도 느리다는 충격적인 사실을 알 수 있었다.
이제 와서 언어를 바꾸기에는... 온라인수업에 숙제에 수행평가에 시간이 없었으므로 그냥 돌리기로 하고... 3일 정도를 돌렸는데...
작업량 때문인지 내가 아치리눅스 설정을 이상하게 한 탓인지 컴퓨터가 작업 돌리기 싫다고 파업을 했다. 갑자기 절전모드가 되더니 다시 깨어나지 않는다... 해서 약 60%정도인 864만 3천개 문서만 분석이 돌아갔다. 중간부터 다시 돌리는 기능을 넣어놔야 했는데... 때는 이미 늦었다.
다시 돌리려고 했는데... 40% 진행되고 나서 또 같은 현상이.. 일어나서... 그렇다. 그냥 864만개로 벤포드법칙을 검증하기로 했다.
아래는 그렇게 문서 864만개에서 수집된 약 1.5억개 수의 데이터이다.
- 21840855개
- 20925695개
- 17278068개
- 16945019개
- 19443783개
- 16472483개
- 15323326개
- 16066190개
- 15682158개
4. 검증을 해보자
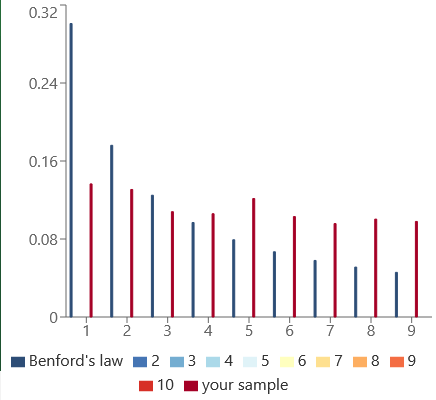
이게 그래프다. 파란색이 이론값, 빨간색이 실측값인데 일단 1하고 2가 많긴 한데... 드럽게 안맞는다. 왜 그럴까?
우선 1. 위키피디아 자체 문법에 숫자가 있을 경우를 생각할 수 있다. 특히 5의 경우 영문 위키피디아 분석 돌리는동안 남은 코어로 돌린 한국어위키피디아 분석에서도 동일하게 1, 2에 이어 높게 나타났다. 이는 숫자 '5'가 위키피디아에서 특수한 용도로 쓰인다는 것을 시사한다.
그리고 2. 수치와 상관없는 난수 (페이지에 포함된 파일 id 등)을 분석에서 제거하지 못해, 그대로 측정되었을 수 있다. 만약 그렇다면 모든 데이터 값에서 같은 수를 빼었을 때, 5를 제외하고... 벤포드법칙과 어느정도 일치하는 구간을 찾을 수 있을 것이다. 나는

각 숫자별로 140만개를 똑같게 제거했을때(난수값은 나타날 확률이 동일하므로) 5를 제외하고 이론값과 그래프가 어느정도 일치하는 모습을 보였다.
카이제곱검정을 통해 데이터의 유의미성을 검증하려고 했는데... 카이제곱검정을 시행하기에 데이터 사이즈가 너무 크기 때문에 (카이제곱값이 42만...)
Cramer V 계수를 이용하여 데이터의 유의미성을 검증하였다.
계산결과 데이터의 Cramer-V 계수는 약 0.248로 이론값과 보정값 사이에 연관성이 충분히 있음을 나타내고 있었다.
즉, 영문위키피디아에 있는 숫자들은 어느정도 벤포드법칙을 따르고 있었음을 알 수 있었다.